啊啊啊!!!好可爱啊!用做头像、朋友圈背景还是挺不错的。
此处的图片经过压缩:


章鱼猫宝宝好可爱捏.


一张一张下载太麻烦了!直接用爬虫爬,在网上找到了两套源码,不过均已失效,而且只能爬取主页155张展示图,代码并不完整,而且只能下载到png格式的,实际上还有jpg和gif动图的,所以改人家代码的成本还不如自己写了呢。
先看效果:
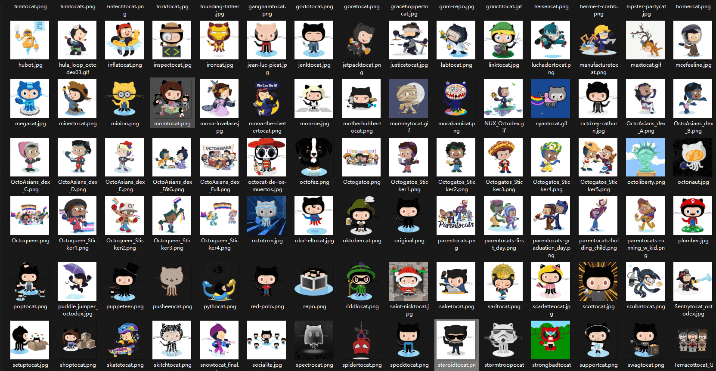
代码运行结果:
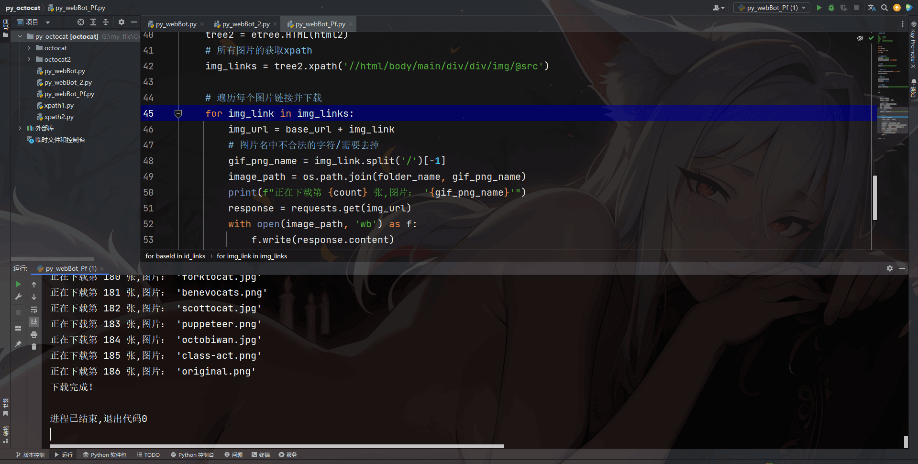
接下来是代码:
# coding: UTF-8
"""
@IDE :PyCharm
@Author :娄南湘先生
@Date :2023/12/9,0010 11:39
"""
import os
import requests
from lxml import etree
import time
# 创建一个octocat文件来保存图片
folder_name = 'octocat'
os.makedirs(folder_name, exist_ok=True)
# 站点URL
base_url = 'https://octodex.github.com'
# 获取网页内容
response = requests.get(base_url, verify=False)
html = response.text
# 解析HTML
tree = etree.HTML(html)
# 让子弹飞一会儿
time.sleep(3)
# 后半部分的链接xpath
id_links = tree.xpath('//html[1]/body[1]/main[1]/div[1]/div/div/div/h2//@href')
# 计数器
count = 1
# 遍历每个展示图像下的子链接
for baseId in id_links:
base2_url = base_url + baseId
# 获取每个当前主图像下面的子链接
response2 = requests.get(base2_url)
html2 = response2.text
tree2 = etree.HTML(html2)
# 所有图片的获取xpath
img_links = tree2.xpath('//html/body/main/div/div/img/@src')
# 遍历每个图片链接和下载
for img_link in img_links:
img_url = base_url + img_link
# 图片名中含有不合法的字符/需要去掉
gif_png_name = img_link.split('/')[-1]
image_path = os.path.join(folder_name, gif_png_name)
print(f"正在下载第 {count} 张,图片: '{gif_png_name}'")
response = requests.get(img_url)
with open(image_path, 'wb') as f:
f.write(response.content)
count += 1
print("下载完成!")
这里记录一个遇到的问题:
选择用xpath语句定位图片地址,因为猫猫们都有自己的名字,所以直接定位到相对应的样式id就好了。

一开始我这么想的,后面实现的时候发现有很多可爱的猫猫没有被下载,因为它们后面接的链接不是id,比如:
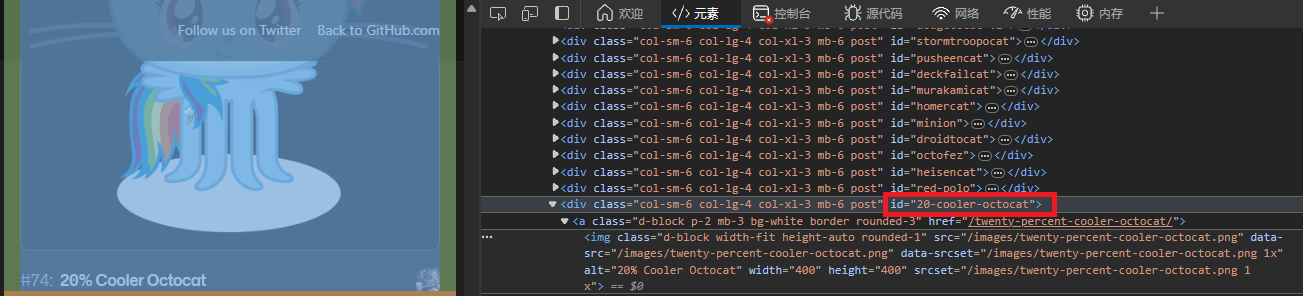
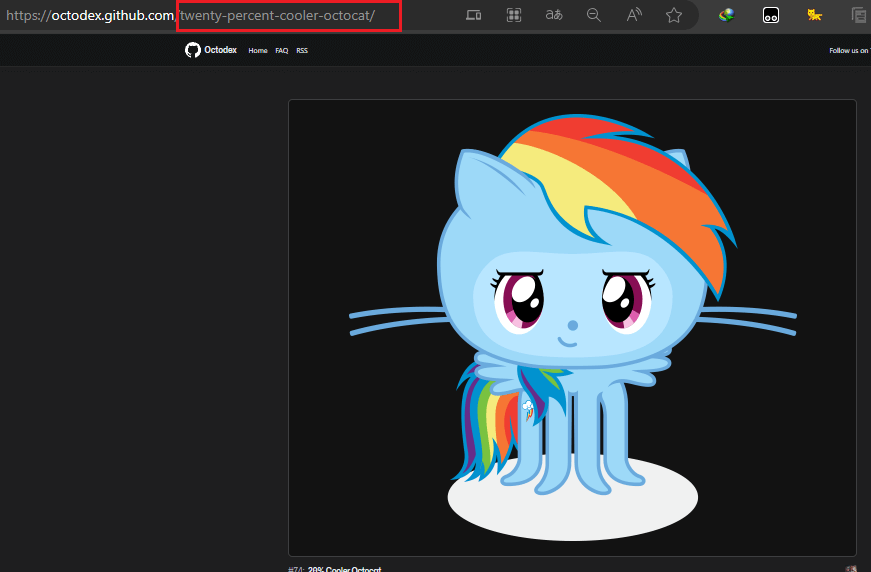
所以这里我只下载到了164张,后面选择定位到href得以解决。

所用的工具xpath在edge插件扩展中下载:

如果你不想运行代码,图片也全部打包在这里:(上传日期:2023年12月10日)
链接:https://pan.baidu.com/s/1Rr9XLcFkrAzNDngDi5NZRQ?pwd=1234
提取码:1234
想要我的ide背景?也在上面的压缩包中
声明:
Octocat形象版权为Github所有,请勿将其作为商业用途,此处代码仅作学习研究使用,如有侵权行为与本人无关!
—-原创文章!转载标明出处!